What is Paima Engine?
Paima is a Web3 Engine optimized for games, gamification and autonomous worlds that allows building web3 applications in just days
Notably, its key features are that it
- Enables you to deploy your game to leverage multiple chains and modular stacks at once in a single unified user and developer experience
- Allows building onchain games with web2 skills
- Protects users even in the case of hacks allowing brands to build web3 applications without worrying
- Speeds you up to make weekly releases a reality instead of most web3 games which are release-and-pray
Paima supports multiple chains out of the box, making it a fully modular rollup framework.
Key technologies that enable this
If you prefer explanations in video form, we have a high-level summary video that explains some of the core benefits of Paima Engine.
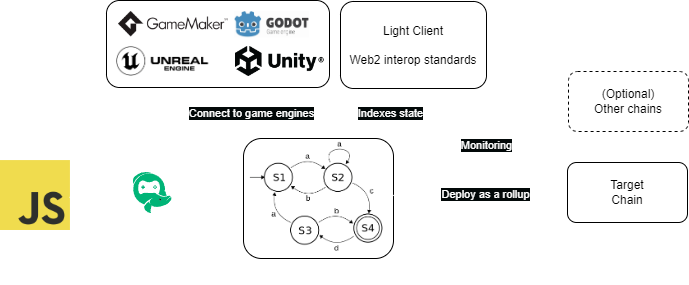
State machines as Sovereign Rollup L2s
Rollups come in many forms, each converting execution costs to storage costs in their own way:
- Optimistic rollups: run the calculation offchain, then store all the data required to execute the function (just data, no execution) along with your locally computed value for the result. Only actually run the execution if somebody believes the result you posted is incorrect ("fraud proof").
Popular examples: Arbitrum, Optimism - ZK rollups: run the calculation offchain, then store all the data required to execute the function (just data, no execution) along with your locally computed ZK proof of the result.
Popular examples: ZK Sync, Starknet, Polygon zkEVM - Sovereign rollup: run the calculation offchain, then store all the data required to execute the function (just data, no execution).
Popular examples: Rollkit, most infra for Bitcoin
Paima is a framework for creating app-specific layer 2s (L2s) as sovereign rollups. That is to say: apps publish transactions to a blockchain for ordering and data availability, but uses its own code to determine the correct app state.
Another way to describe this is first to note that every mathematical function has 3 key properties:
- Function inputs
- Function definition
- Function outputs
For Paima, the inputs are stored on-chain (which guarantees determinism), the function definition is packaged as an executable for running the app, and the function output is the resulting state machine after applying the state transition (with the result queryable through an indexer that is part of the game node).
You may sometimes hear this referred to as a "pessimistic rollup" because nodes need to re-execute transactions to check the validity of the chain instead of optimistically being able to assume correctness. This mirrors many ideas of replicated state machines.
Data Projections (co-processing)
These state machines can evolve based on L1 updates such as
- New blocks/transactions
- Contracts on the L1 being updated
- Accessing historical on-chain state
- Reading updates from other L2s/rollups deployed on the blockchain
- Passive time and timers (game ticks)
Or even more complex transition rules.
In other words, it allows building event-driven (or sometimes called loop-driven) architectures.
A great example of this is using the L1 blockchain as the source of randomness, which avoids every game having to re-implement a randomness oracle from scratch. Note that the data you can access through projections is actually more data than can natively be accessed by a smart contract (in fact, smart contract platforms usually very strictly limit the kind of data contracts can access). Co-processors are a growing field in web3 try and enable applications to bypass these restrictions to access more data and so in that way Paima Engine is a gaming-focused co-processor.
This is possible as sovereign rollups can project L1 state to the L2. A deep dive into data projections and the full modular gaming rollup stack can be found in this video.
Sharded rollups as a multichain co-processor
Paima allows you to do computation in your state machine over an aggregate view of multiple chains. This allows you to, in a sense, to shard the state of your application in multiple locations such as deploying your game to a cheaper chain yet still leverage NFT marketplace / DeFi liquidity from larger networks without requiring a bridge (since you are natively monitoring both chains). Note that this is done without giving up any sovereignty of your game logic. This is powered by having data projections from different networks aggregated into the same state machine. This allows your games to scale like DEX aggregators in the sense that they can leverage and aggregate features from multiple ecosystems to provide the best experience for their users.
Stateful NFTs and NFT compression
Thanks to projections, we can access the state of L1 NFTs from Paima. We can then interpret the output of the state machine as extra information associated to these NFTs allowing them to evolve over time based on user actions on the L2.
In a sense, you can think of this as an NFT compression protocol. Instead of having to mint a lot of static NFTs on the L1, you can instead mint a minimal set of NFTs on the L1 and then evolve them based off the state of the L2.
Parallelization (asynchronous compute) to handle over 10k+ tps per game
Paima state machine L2s are not only significantly more efficient than the EVM, they also supports optionally running state machine updates in parallel (not natively available in the EVM), allowing games and apps to massively scale by, for example, having different PVP matches or different maps in an MMO run in parallel.
Cross-chain/multichain and sequencing with Paima Whirlpool
Paima allows creating rollups that aggregate multiple chains together. Natively, Paima supports users submitting transactions to these underlying chains manually themselves, but this is a high burden for users - especially as the number of chains applications connect to has grown over the years thanks to the growing trend of building modular chains. To tackle this, Paima focuses on chain abstraction with Paima Whirlpool - a suite of tools to help translate complex interactions to something that integrate seamlessly with Paima Engine.
L2-level Account Abstraction
Currently there is a large focus on account abstraction which powers smart contract wallets to create systems more flexible than the default public-key wallets created by most cryptocurrencies.
Paima Engine can enable much more flexible account abstraction by providing this functionality at the L2 level when needed, which allows easily validating cryptographic primitives that would not otherwise be available at the L1.
Based rollup & Sequencer SDKs
L2s created with Paima run as a based rollup - that is to say its sequencing is simply done by the DA layer (which is generally the underlying L1) and so it fully inherits its finality. This means that Paima L2s can be run without a sequencer (sometimes referred to as "self sequencing") and fully inherit the decentralization and security of the L1, and do this without the downsides traditionally associated with based rollups thanks to Paima's support for parallelization.
Although apps may not always need sequencers, they can still improve scalability and also help user onboarding. Notably, they can
- Batch transactions together to amortize transaction fees
- Cover the transaction fees for specified users through meta-transactions (ex: free txs for users who hold a specific NFT, who delegate to a stake pool, or who paid on a separate chain).
Thanks to the flexibility of the batcher system, Paima can even support games built without an enshrined sequencer - that is to say environments with multiple sequencers where anybody can choose to run their own decentralized sequencer for the game and monetize it how they want. This give the benefit of sequencing without the centralization or censorship concerns.
Cross-chain NFTs
Projects may want to allow users to play games with NFTs hosted on chains separate from where the app was deployed. For example, the game is deployed on a DA layer, but is playable from NFT living on separate L1.
The goal, therefore, is to try and support connecting these NFTs to state machines in different ways with different trade-offs to empower games to take advantage of approach that works best for them. Notably, we are actively working on integrating:
- Multi-layer monitoring (Sharded rollups mentioned above)
- Storage proofs
- Mirroring
- NFT bridging
- Message passing
Paima Engine helps developers overcome problems with connecting multiple ecosystems (even when monitoring multiple chains, different chains have different block times and finality making solutions non-trivial) by providing a wide-variety of options to different use-cases including special handling of cases where we need to assert the user still holds the NFT (in other words, they haven't sold the NFT since the last time we got an update from the different chain about the ownership status).
You can find more about the idea here
Non-custodial L2s
Most blockchain apps and L2s are custodial in nature. That is to say, to use them you first have to deposit your funds into the app/L2. This is dangerous because it means that user funds are at risk if the contract that is custodying user funds gets hacked, or if the L2 goes offline (sometimes called a "proposer failure" if nobody can bridge L2 funds back to the L1, or "sequencer failure" / "liveness failure" if the L2 state itself can no longer be advanced).
Paima however, thanks to its projective rollup support, can allow users to keep full custody of their assets while using games & apps written using Paima. That is to say, even if your app gets hacked or all batchers for a game go offline, user L1 assets are not at risk. This makes Paima a very safe way for brands to deploy onchain applications and brand reputation risk in the case of a hack is minimal. Technically speaking, it means liveness is ensured thanks to self sequencing and proposer failures are simply not possible as there is no need for proposers in the first place.
Additionally, this also helps a lot with user acquisition as empirically most users are not comfortable bridging their NFTs from L1→L2 due to bridge security concerns.
Lastly, it also helps with liquidity & composability, as its means you don't have to fracture assets between L1 and L2.
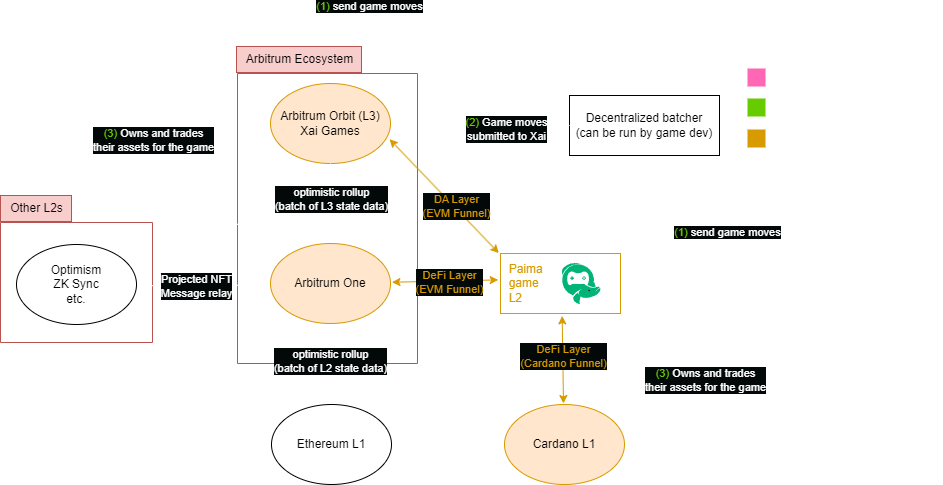
Example game
To help visualize how these components help build a game, we will show an example game that settles to an Arbitrum Orbit L3 (Xai Games) as its DA layer as it uses a data availability committee making data cheap. However, since almost no users have assets on Xai, it uses Paima's built-in batcher (sequencer) SDK and account abstraction layer to allow players to play gasless from other chains.
Similarly, to give additional liquidity for NFTs for the game, it natively supports minting NFTs on the two of the largest ecosystems in crypto by marketcap (Ethereum through Arbitrum One and Cardano). Since there are many EVM ecosystems and we cannot possibly monitor them all, we use a projected NFT contract connected to a message relayer to support NFTs on the other chains (more on this topic in a later section).
Data availability (DA) layer support
Paima supports the following as DA layers:
- EVM (default)
- Avail
We provide the choice, because using a DA layer makes resync of rollup state significantly cheaper & faster.
- EVM: syncing rollup state requires running an EVM fullnode (expensive & heavy)
- DA: syncing rollup state, thanks to data availability sampling, just requires running a light-client (still gives fullnode-like security), and it only downloads the subset of information required for your rollup state!
More technically speaking, we support not just typical rollups, but also building both volition and validiums.
ZK (Zero-Knowledge Cryptography)
ZK cryptography is often used in Web3 for two different properties:
- Its ability to succinctly prove the state of a system (kind of like a very efficient compression system)
- Its ability to handle functions with private inputs
Both these use-cases are of interest in games, as being able to prove world state helps with composability of worlds, and private inputs allow games with private state (ex: fog of war) and can also help with compliance (ex: being able to prove you know information without revealing the sensitive information publicly)
Paima already comes with ZK layer support, and we are working with Zeko (based on Mina Protocol) to enable app-specific ZK rollups as well. You can learn more about the architecture of our ZK layer here.
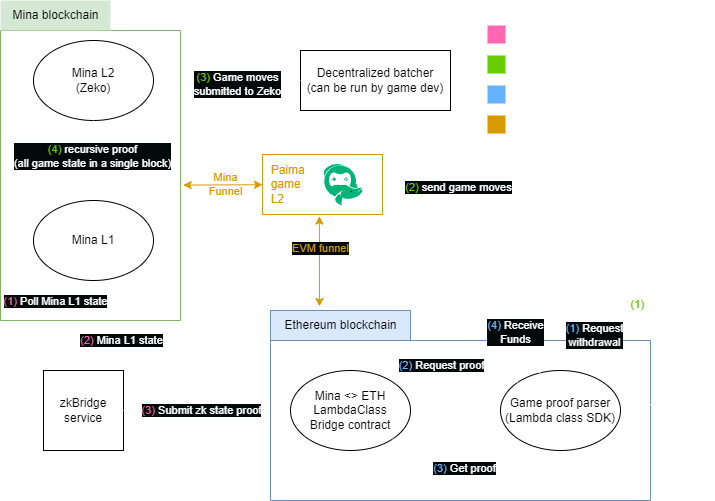
Example game
This game is a team battle game that leverages recursive SNARKs provided by the Mina blockchain for private state and state-channel-like scalability. However, Mina has very few users. To get around this issue, it allows users to deposit funds into the game from Ethereum and unlocks winnings using a ZK proof of victory. However, since ZK proofs only settle to Ethereum once a match is over (plus a few minutes of overhead). To allow writing a smooth UX where the whole game logic is a unified experience, the game is written using Paima Engine that monitors both Mina for the gameplay and Ethereum for the deposits and payouts.
Ongoing work
Storage proofs
We plan to integrate storage proof mechanisms natively into Paima Engine. This will allow you to have optimistic (fast) UI updates shown to users of your rollup, while on the backend settling proofs across chains where required.
State Channels (Short-lived Shards)
Paima's parallelism feature already serves as the first step towards a future system to have game shards to help games scale as needed. These shards could be long-lived, or be ephemeral such as state channels that facilitate use-cases like 5v5 fights where a state channel could be opened between participants and settled when the game is over.
AI
A few common demands have emerged for integration of AI into autonomous worlds:
- Affecting the appearance of user's NFTs
- Affecting the game world state (either as NPCs like in Smallville or as a god that controls the world)
Since autonomous worlds do not necessarily have a central company driving the evolution of a game, this kind of autonomous action powered via AI and LLMs is an interesting alternative. However, since AI is not something that can be run computationally onchain, the AI is often run similarly to a sovereign rollup - as a uni-directional bridge. This is not ideal as it means you cannot "close the loop" by having the AI result come back and modify the in-game world.
Paima is tackling both of these use-cases:
- Paima already supports basic deterministic AI integration and you can see an example of this in a proof-of-concept game called Oracle RPG where user Stateful NFTs dynamically evolve based on AI computation
- We hope to expand AI support to allow more complex use-cases such as villages powered by AI agents that hold Stateful NFTs. This will be done through integration with Shinkai Network.
P2P layer
Currently, Paima works by updating the world based off on-chain transactions. However, a P2P layer between players could improve the experience.
Notably,
- Currently, the game tick rate to that of the underlying chain (1~2 seconds on many L1s/L2s). In the future, we will build a way to connect Paima games to a P2P layer so that transactions can be broadcast between users faster than it takes for the txs to appear on-chain, allowing for a faster experience assuming players have honestly submitted their transactions (optimistic updates).
- Users want to send visual updates to each other that do not be to settled on-chain, such as chat boxes.
Commit-reveal
Currently, for most commit-reveal schemes, users have to be online to make the reveal. In online games where everybody has 24hrs to commit their next move, this is not ideal as it means all players need to come online at the end of the round to reveal their move.
Solutions for this problem often involves more complex cryptography and too many "reveal" transactions to scale properly. However, Paima can very naturally integrate decentralized timelock encryption protocols for games that need it.
Why Sovereign rollups?
There are a few ways of powering scalable applications on-chain. Paima is built using Sovereign Rollups instead of two other common techniques: Optimistic Rollups and ZK Rollups
Optimistic Rollup disadvantages
This section is written assuming an EVM-based optimistic rollup
- Apps have to be written in Solidity (if deploying to an existing optimistic rollup like Arbitrum) or be written to be compatible with the fraud-proof system (if an app-chain) which limits flexibility and generally means it's not composable with standard game development tools
- App performance is bottlenecked by EVM performance. Even implementing parallelization (very common for games) requires a complex sharding system, greatly increasing ecosystem complexity.
- Limited to EVM's data model (reads and writes are slow)
- No support for passive time, as you cannot fraud-proof the passage of time. However, passive time is hugely important for games (ex: timers)
- Requires Solidity boilerplate (not accessible to most game developers)
- Limited projection and stateful NFT support (optimistic rollups have limited projective rollup support). This limits the user base as many users will not want to bridge their NFTs from L1→L2 to use the app and also hurts liquidity & composability
- Apps have very long finality as they may get rolled back due to fraud proofs
ZK Rollup disadvantages
ZK Rollups are primarily a computation solution. Although handling computation is important, a lot of apps (especially games) are more data management platforms (user accounts, encoding how the accounts update over time, etc.). Therefore it often makes more sense to have a sovereign rollup as the base for the game, and only use ZK when required on specific parts of your app (such as associating ZK proofs to stateful NFTs that may represent things like results of a match)
If ZK is enforced or if the whole application needs to be written as one giant ZK circuit, you will run into the following issues:
- ZK performance is generally slow for large circuits, making it very hard to build complex games
- ZK platforms typically enforce a global maximum on circuit sizes for zkApps deployed to their platform, which complex games will exceed
- ZK circuits are currently still hard to write. There are some languages and efforts to simplify this, but they generally still require manual fine-tuning to try and minimize circuit size as much as possible
- No support for passive time. This may be, depending in the use-case, replaceable by a Verifiable Delay Function, but this is much more complicated and not as powerful
Sovereign Rollup disadvantages
Unfortunately there is no "free lunch", and so usage of sovereign rollups comes with some disadvantages as well. Keep in mind while reading this that Paima overcome these deficiencies by combining its sovereign rollup layer with its native support for L1 smart contracts and its ZK layer. You can learn more about this in our blog posts here.
Extra work for trading L2 assets on the L1
Although assets that stay on the L1 are supported, if assets are stored on the L2, extra work is required to make these assets from the L2 available on the L1 (that is to say, supporting the ability to put $5 into the L2, make some money, then take $10 out require extra work). Paima Engine supports this through its concept of inverse projections which supports both NFT and fungible tokens. You can learn more about this in our blogpost.
Optional compatibility with other L1 dApps
Paima gains a lot of its strength from shifting game state management into the L2. This state can be accessed on the L1 depending on how you create your game (ex: by using the ZK layer), but isn't required.
This gives developers using Paima a choice: do they want focus on compatibility with other L1 apps (requires extra work/cost even though they do not have a product-market fit yet), or focus on building their decentralized game and improve composability after.
Custom indexing for rollup state
Games in Paima do not necessarily run a single stack, so depending on how an app is built, leveraging a single L1's tooling may not be sufficient to get proper insight into the rollup state.
To tackle this, Paima Engine comes with many standards and its own indexer system to allow you to easily visualize and explore your rollup's state.